The Marin team's goal is to train a frontier large language model. This requires significant resources across a variety of providers and accelerator types. Our Iris scheduling system has allowed us to effectively make use of these precious resources using a custom global scheduler; in the months since rollout, our sustained concurrent TPU usage has roughly doubled.
We're aiming to train a completely open (data and methodology) frontier-level LLM by the end of 2026. This requires enormous amounts of compute: our current estimate is that our final pre-training run will require millions of GPU hours of compute, with a similar amount of compute beyond that for post-training and reinforcement learning (RL). Thanks to our generous sponsors, we've been fortunate to receive enough accelerators to do this. Even to get this far has required significant resources, for which we're grateful: access to Google’s TPU Research Cloud has let us refine and improve our model recipes, improve our data mixtures, and dial in our targets for our larger runs.
Given the cost and scarce availability of ML (machine learning) accelerators, it's important to us to use them responsibly. For us, this means ensuring that accelerators are always doing useful work, and also that the work they're doing is efficient. An idle accelerator is a waste, but so is an accelerator that's operating at 1% efficiency.
One quirk of our operating environment is that our compute budget has been dominated by preemptible compute: large amounts of accelerator quota, but no guarantees on whether or how long we could make use of the machines. Furthermore, the availability of resources depends heavily on time-of-day and region: for example inference friendly accelerators will disappear during peak periods and recover overnight.
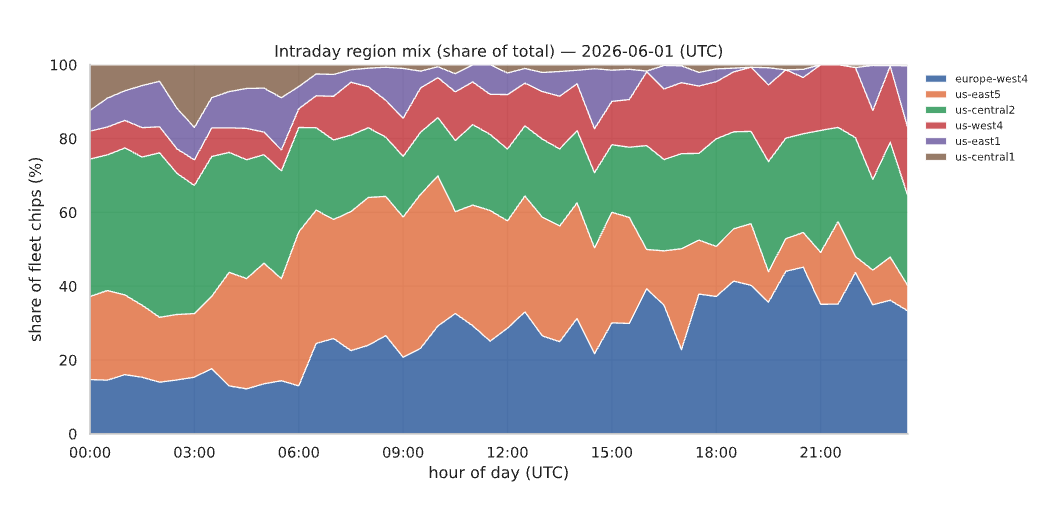
Leveraging these preemptible and region varying accelerators effectively is challenging, and a large part of why we developed our own system for scheduling, which we call Iris.
Initial Steps
Marin's initial approach to cluster scheduling built on the popular Ray distributed computing framework. Ray was brought in to solve a much simpler problem: gang-scheduling for TPU slices for single training runs. TPUs before v7 are allocated in "slices." In larger slices (> 4 or 8 TPUs), the TPUs are partitioned across multiple VMs (virtual machines). A user model needs to be assigned to exactly the set of VMs for a particular TPU slice, and the user program needs to coordinate work so it takes the same actions across all TPUs in a slice.
For the handful of users and single region work we were doing at the time, Ray served adequately. Once Ray was used in one place, it became natural to try to use it elsewhere. Ad-hoc Ray usage cropped up for data-processing pipelines, training sweeps, and coordination. As we started onboarding more researchers, we needed a way to share TPUs across them. It thus became natural to use a shared Ray cluster across users: this let jobs scavenge idle CPU from a running TPU job, or jump onto an idle TPU easily. This was easy to deploy and seemed to work well—initially.
Unfortunately, over time, the limitations of our Ray deployment became more and more pressing. Our usage diverged from that of most Ray users, and we were suffering for it. A few of our challenges included:
- The Ray autoscaler operates per region. Because our compute is scattered across different regions, we needed a Ray cluster for every region we had TPUs. This forced users to make an up-front choice about where to put a job. It led to "camping" on a region where they had found resources in the past, leaving other regions idle.
- Ray jobs ran without isolation on our VMs. Crashed jobs could lead to TPUs being in a "stuck" state: the VM appeared healthy but the TPU was unusable, breaking any future jobs assigned to that VM. We had to invest in our own complex machinery to try to automatically recover VMs.
- By default, Ray relies on workers remaining available to provide access to logs data. Job logs would be lost after worker preemption, making it hard to do post-mortem analysis or debugging.
Finally, Ray's built-in autoscaler and scheduling system was struggling to handle the number of users and jobs we were throwing at it. At our peak, we needed to reset busy clusters almost daily, and we developed workflows to try to restore cluster state between restarts.
Debating alternatives
As time went on, we found ourselves spending more and more time managing and working around Ray and not enough time actually training models. We needed to figure out a sustainable solution.
To the Ray team's credit, they were responsive to many of our requests for support, but understandably, our rather odd use case was not a priority. The primary recommendation for deployments like ours was to start using Ray on top of Kubernetes, with Kubernetes as the scheduler and Ray as the communication layer.
We considered this, but while Kubernetes would solve some of our stability and isolation issues with Ray, it wouldn't address many of our other long-term challenges around global scheduling and autoscaling. In particular, we had the following reservations.
- At the time, Google's Kubernetes engine didn't support reserved instances, meaning we would have needed a separate scheme for our reserved and preemptible compute.
- Kubernetes scheduling would still be per-region, meaning we'd need to manage separate clusters or cobble together a meta-scheduler on top.
- Kubernetes' built-in scheduling engine doesn't support gang-scheduling; it requires extensions like Kueue to handle this scheduling correctly. In theory, systems like Multikueue would give us multi-region support, but these are still in early development.
Also, while we started this work operating on one platform, we knew that we wanted to leverage accelerators from other platforms in the near future. The potential environments available to us varied dramatically, from bare-metal platforms with our own SSH to Slurm-managed clusters.
After debating our options, we realized that what we wanted was a consistent cluster-scheduling interface that satisfied our unique constraints, regardless of the underlying implementation. We could then evolve our implementation or backend as needed, without disrupting users.
Design and development
Recall that our system needed to satisfy a number of unique requirements.
- Easy, Ray-like job submission: Python scripts with simple resource specifications
- Cross-region scheduling
- Gang-scheduling for multi-VM workloads
- User job prioritization and preemption
- Including TPU-topology aware scheduling: the scheduler needed to know that evicting smaller TPUs will free up larger slices
- Multi-platform and accelerator support
With this in mind, and taking lessons from previous experiences with Ray, K8s, and Google's Borg and XManager systems, we began developing the design for our Iris scheduling system. Given our common pattern of replicated jobs for data processing, we decided to adopt Borg's "replica" system, where a top-level job can specify that it should be replicated into one or more individual "tasks," making a "task attempt" the real unit of scheduling.
For users, we wanted to preserve the simple feel of Ray scheduling. We landed on using a resource specification for jobs, with helpers for common accelerator types:
ResourceConfig.with_tpu(
"v5litepod-16",
slice_count=1,
cpu=32,
ram="128g",
disk="50g",
)
A job request then consists of the resources, along with a specification for what to run on those resources. Like Ray, Iris supports providing a callable function or a top-level script to run on the cluster:
job_request = JobRequest(
name=name,
entrypoint=Entrypoint.from_callable(entrypoint_callable, args=list(args)),
resources=resource_config,
environment=create_environment(env_vars=env, extras=extras_for_resources(resources)),
)
handle = client.submit(job_request)
Unlike Ray, Iris tasks do not communicate via a distributed object store. Instead, Iris provides a basic actor system for tasks to directly communicate with each other. Tasks locate each other's active servers via the Iris endpoint registry, which is used to map names to active server addresses.
Job requests are submitted to the Iris controller, which is responsible for launching and dispatching jobs. Job replicas are first expanded into their constituent tasks, and then the job resource specification is converted to a uniform set of constraint expressions. When using its native GCP (Google Compute Platform) scheduler, Iris uses constraints to determine where a task can be scheduled, and when to autoscale and request more compute to satisfy job requests. When working with its Kubernetes backend, Iris constraints are converted into the appropriate K8s and Kueue scheduling requirements, with Iris simply providing a convenient view on top of the K8s cluster status.
The Iris scheduler is global and searches across all regions where we have compute available. This, combined with a set of abstractions we developed to automatically mirror data across regions when needed, allows jobs to be scheduled anywhere we find compute, moving as necessary to where we have resources.
Since we are primarily concerned with training models, and not serving user-facing endpoints, Iris purposefully lacks many of the features expected from more "high-availability" environments, like gradual rollouts and health checking.
Migrating from Ray
To make migration from Ray seamless, we rebuilt our software on top of an abstraction we call "Fray." By building both Iris and Ray implementations for Fray, we could migrate all of our internal code to support both systems without disrupting existing work. This required building out a small actor system on top of Iris to support the small number of distributed RPC workflows we had with Ray as well.
Rollout and user feedback
After the initial design process, our development of Iris was rapid, thanks in part to the dawn of the agentic coding era. However, like for many projects, it took us some time to leverage the tools effectively, and we had to do some rewrites to address "code slop" concerns. We began active development in early January, and our initial rollout began only six weeks later. We turned off our last Ray cluster approximately one month after that.
Switching to Iris changed our community's ability to leverage preemptible resources. The experience has been largely positive, though not without some expected early-adoption pains. Our largest issue was underestimating the load as users gained experience with the system.
Some of the feedback we received from users:
- On the Ray cleanup-reliability gap: "ray doesn't really give us a reliable way to clean up after ourselves when the driver fails"
- On compute availability: "iris giving us a lot of compute right now wow"
- On pulling stats for long-running jobs: "(again very cool we can do that so easily w/ iris)"
- On dashboard performance: "The Iris dashboard feels slow at the moment. It's hard to queue and kill jobs or even check the status of jobs."
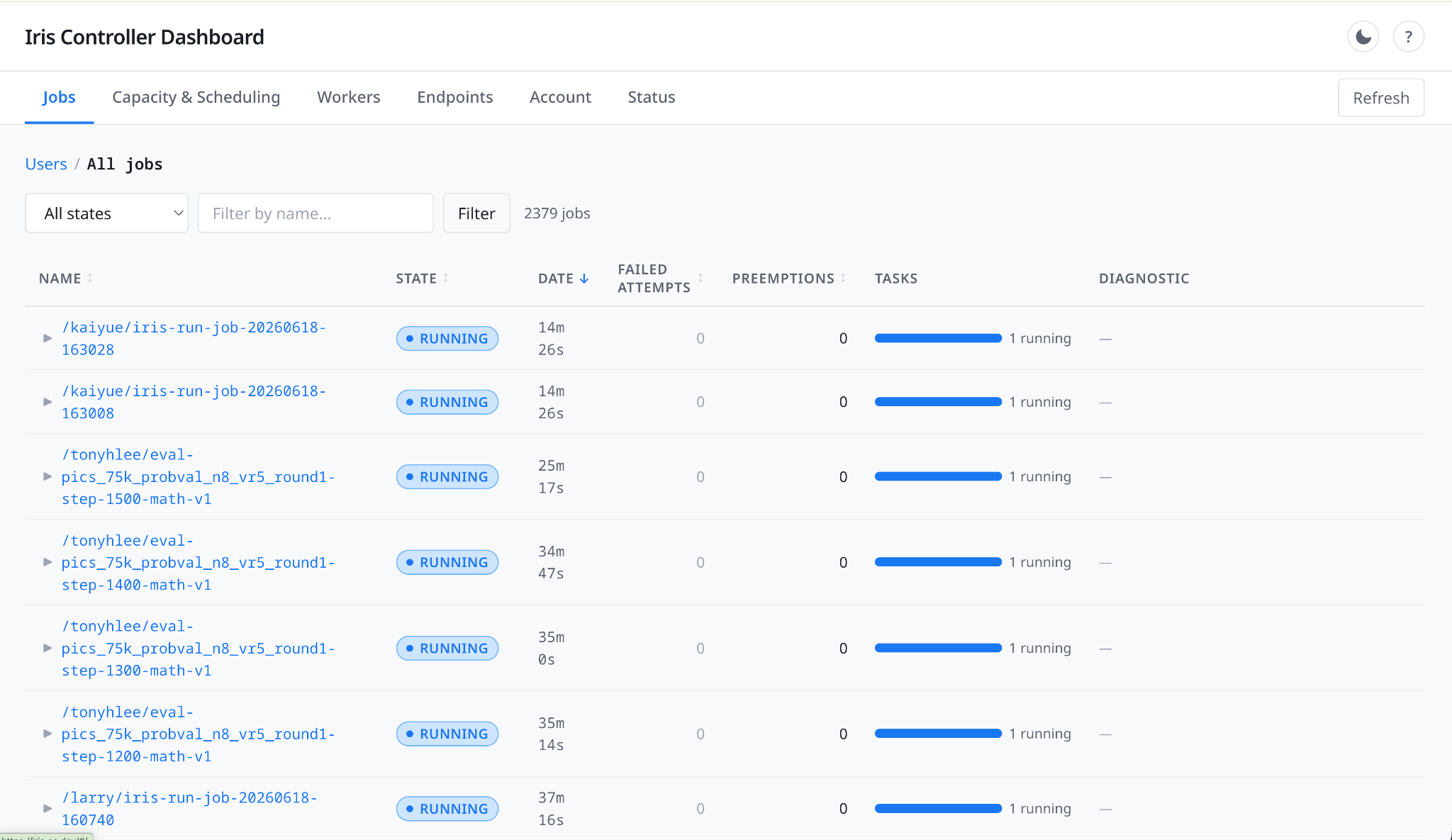
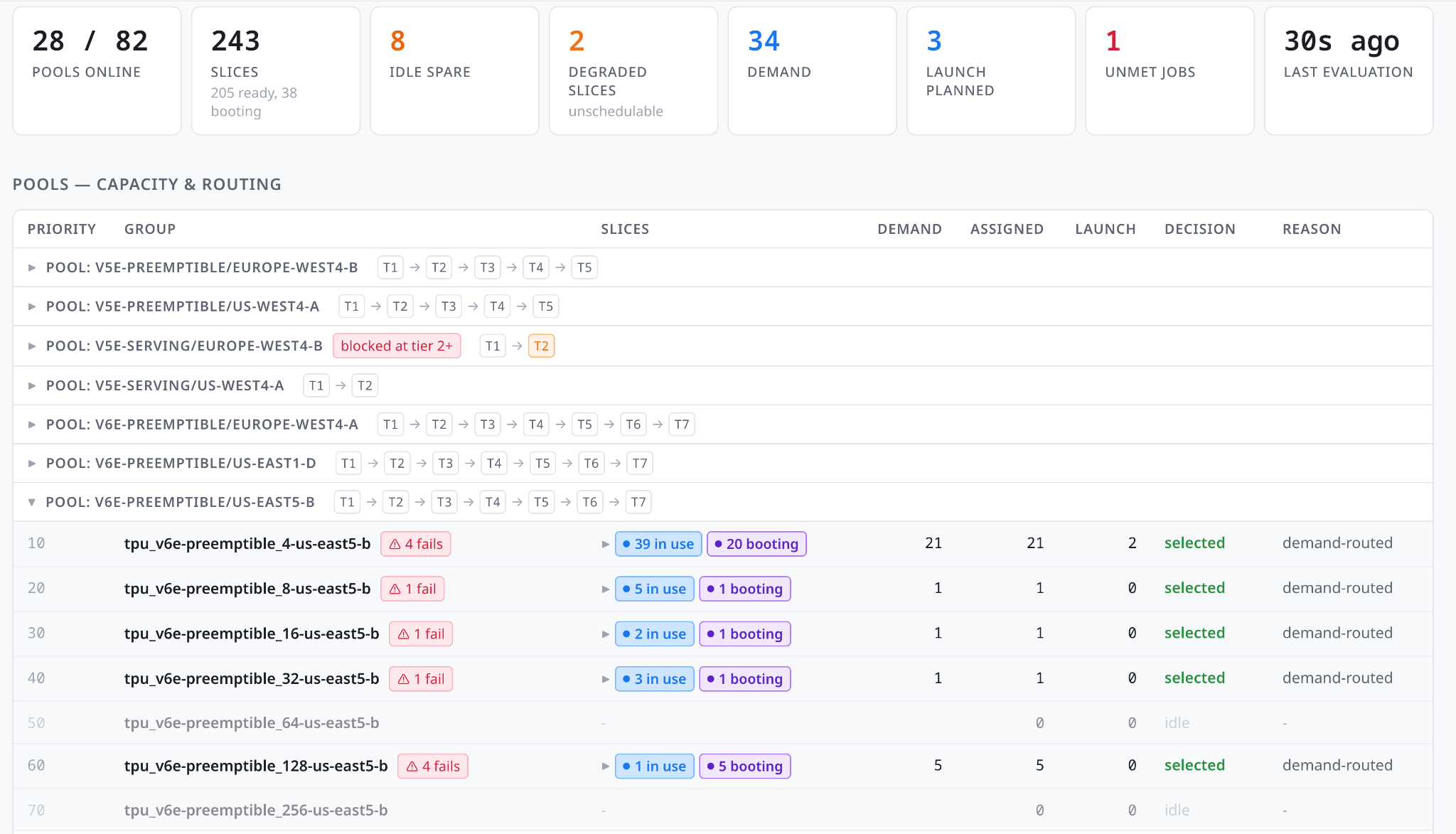
Iris provides the expected dashboards for user jobs (Figure 2) and worker status (Figure 3), giving users a quick way to check the status of the cluster.
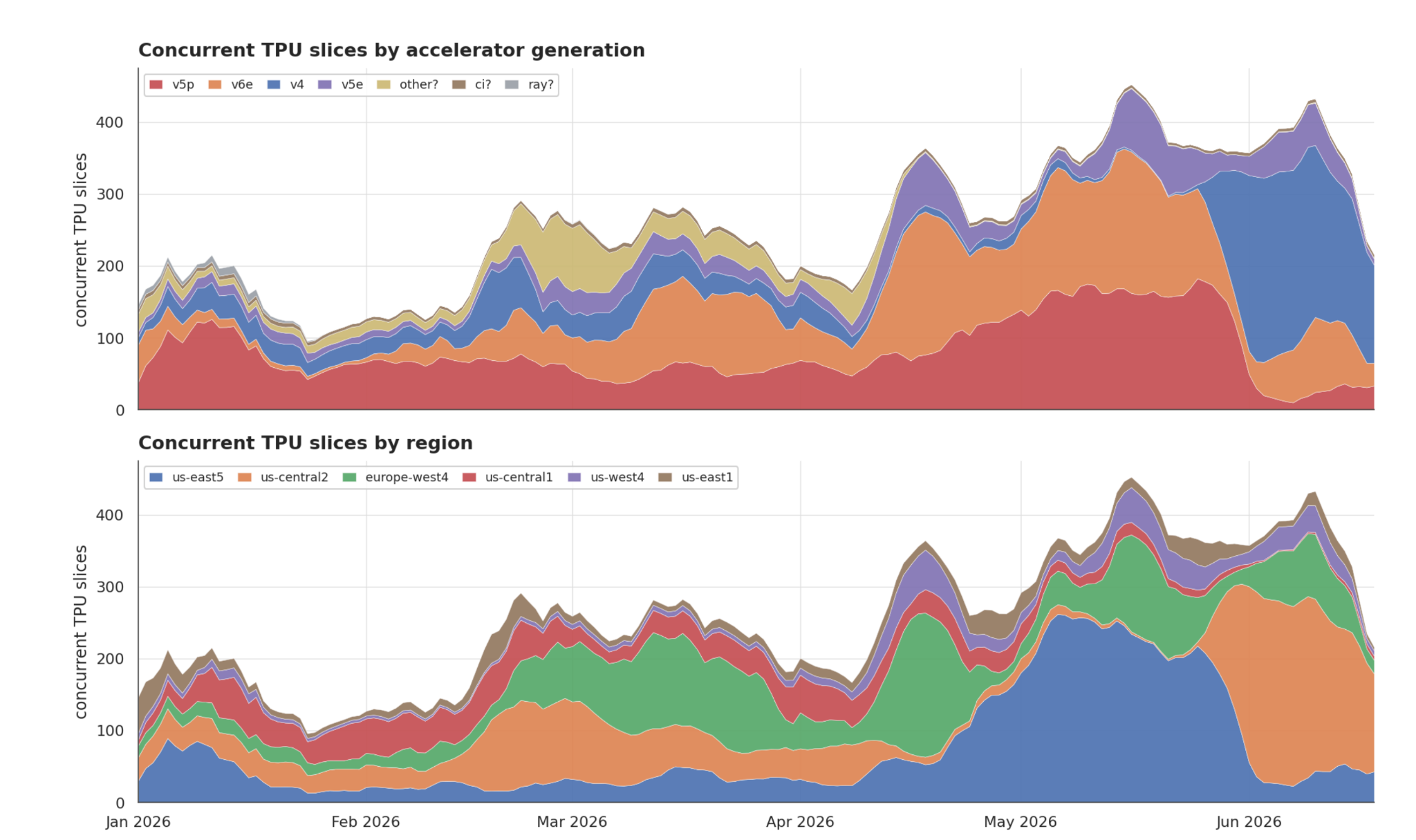
Almost immediately after rolling out Iris, we've seen sustained usage of TPUs climb across both regions and accelerator generations. Before the migration, concurrent TPU slices typically sat around ~150–200, dropping toward ~80–100 during scarce periods. In the weeks after the March rollout, they roughly doubled, reaching a ~350–450 plateau through April and May (Figure 4). New regions came online as well, and europe-west4, us-west4, and us-east1 moved from occasional to regular use.
Next steps
We continue to develop Iris to add new functionality and refine the experience, in response to user feedback. After our initial deployment on GCP, we added a Kubernetes backend to allow Iris jobs to run against Kueue + Kubernetes clusters. We've also rolled out a priority and preemption system to allow long-running batch jobs to make use of TPU resources without blocking higher priority work.
More recently, we've started work to allow a single Iris cluster to manage multiple providers (GCP and Kubernetes), which would give our users a uniform interface for both job specification and dispatch. Again, this is important to us as we want to ensure that we aren't leaving accelerators on the table. We've also started investigating the feasibility of a Slurm backend which would let us dispatch Iris jobs against academic Slurm clusters.
Our end goal with Iris is to ensure that Marin can take advantage of any compute we're given access to, while asking as little of our hardware partners as possible. This ensures that we are responsible stewards of the compute we're given, as well as making Marin a more attractive choice to share compute with.
Although Iris has been a success for Marin, we acknowledge it has many limitations and that it might not be the right fit for many or most other organizations. It's made to help Marin leverage compute effectively for our job types, not to be a generic cluster management service. In particular, we haven't invested in many of the refinements around setup and documentation that would make it easy to use for external users.
If you are curious about Iris or Marin, you can explore the codebase, or join our Discord.
Cite this post
@misc{power2026_cluster_scheduling_with_iris,
author = {Power, Russell},
title = {Cluster Scheduling with Iris},
year = {2026},
month = {jun},
howpublished = {\url{https://www.openathena.ai/blog/cluster-scheduling-with-iris/}},
note = {Open Athena Blog}
}